Learning Gait-Aware Quadruped Locomotion with Temporal Logic Specifications
Anonymous Author(s)
Submitted to the 10th Conference on Robot Learning (CoRL 2026)

Abstract
Reinforcement learning (RL) for quadruped locomotion commonly relies on fixed, hand-crafted, and Markovian reward functions, which limit the interpretability of learned policies and provide no explicit control over gait behaviors. We introduce a framework in which distinct gaits are specified using parameterized constraints expressed in Signal Temporal Logic (STL), including safety bounds, gait synchronization constraints, command tracking objectives, and actuation limits. From these specifications, we develop a reward-shaping mechanism that provides learning agents with a dense and continuous reward landscape that encodes the desired behavior. We define parametric STL templates for three speed regimes (walking-trot, trot, and bound) calibrate their parameters from reference rollouts, and compute rewards using smooth approximations of STL robustness over these rollouts. The resulting rewards provide shaped gradients that are compatible with Proximal Policy Optimization (PPO). We instantiate the approach on Google’s Barkour quadruped robot in MuJoCo XLA (MJX), leveraging simulator parallelization to accelerate training and domain randomization to improve policy robustness. Experimental results show that, compared to conventional hand-crafted rewards, STL-shaped rewards achieve tighter velocity tracking and more stable training performance.
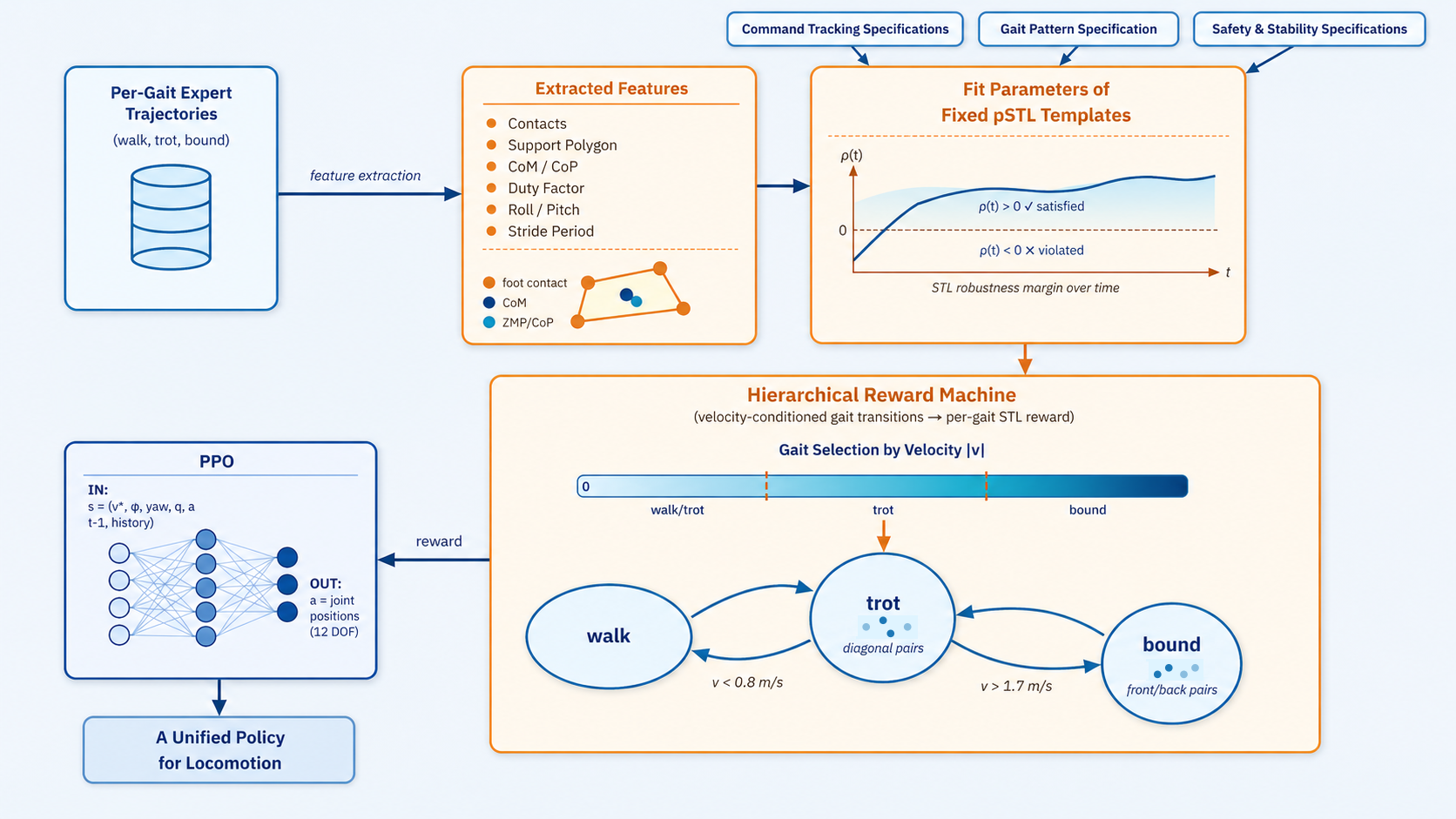
Methodology
Our framework aims interpretable specification-based, gait-aware reward design for quadruped locomotion tasks. The reward component corresponds directly to human-readable requirements.
1. Feature Extraction
We compile trajectory datasets from specialized models corresponding to low-speed, mid-speed, and high-speed regimes. Extracted features include:
- Tracking features: Linear and angular velocities.
- Safety/stability features: Center of Mass (CoM), Base roll/pitch, and slip proxy.
- Contact-pattern features: Stride period, duty factor, and diagonal phase error.
2. Parametric STL (PSTL) Templates
We define fixed PSTL templates for three locomotion modes, fitting parameters using empirical quantiles from the expert datasets.
- Walk-Trot: Characterized by support-rich diagonal locomotion with no flight.
- Trot: Characterized by dominant diagonal 2-contact support.
- Bound: High-speed pair-synchronized running where forelegs and hind legs move in phase.
3. Hierarchical Reward Machine
The final reward is derived from the quantitative robustness of the active specifications within the current temporal window. The active locomotion mode g(t) ∈ {W, T, B} is selected dynamically based on the commanded forward velocity vxcmd. The scalar reward aggregates safety, tracking, and gait structure robustness alongside a torque-effort penalty.
Experimental Results
The locomotion controller is designed for Google’s Barkour vb quadruped robot, modeled and trained using PPO within MuJoCo XLA (MJX). We utilize domain randomization over friction and actuator parameters to robustify the learned policies.
Velocity Tracking & Stability
Benchmark comparison across commanded forward velocities. Each entry reports mean ± standard deviation over 20 rollouts. Lower CoT is better; higher survival and success are better. Success means the average post-warmup forward speed stays within ±15% of the commanded speed.
| vx | STL-based reward | Heuristic-default | Heuristic-best | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CoT ↓ | Survival ↑ | Success ↑ | CoT ↓ | Survival ↑ | Success ↑ | CoT ↓ | Survival ↑ | Success ↑ | |
| 0.3 | 2.1 ± 0.1 | 1.0 ± 0.0 | 1.0 ± 0.0 | 2.1 ± 0.1 | 1.0 ± 0.0 | 0.0 ± 0.0 | 1.2 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 0.5 | 1.5 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.3 ± 0.0 | 1.0 ± 0.0 | 0.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 0.7 | 1.2 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.1 ± 0.0 | 1.0 ± 0.0 | 0.1 ± 0.2 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 1.0 | 1.2 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.5 ± 0.0 | 1.0 ± 0.0 | 0.8 ± 0.4 | 1.2 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 1.3 | 1.1 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.3 ± 0.1 | 1.0 ± 0.0 | 0.3 ± 0.5 | 1.3 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 1.6 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.2 ± 0.0 | 1.0 ± 0.2 | 0.3 ± 0.4 | 1.4 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 1.9 | 1.1 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.2 ± 0.1 | 0.5 ± 0.5 | 0.0 ± 0.0 | 1.4 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| 2.0 | 1.1 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.3 ± 0.1 | 0.5 ± 0.5 | 0.0 ± 0.0 | 1.4 ± 0.0 | 1.0 ± 0.0 | 0.1 ± 0.2 |
| 2.1 | 1.1 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.3 ± 0.1 | 0.3 ± 0.4 | 0.0 ± 0.0 | 1.4 ± 0.0 | 1.0 ± 0.0 | 0.0 ± 0.0 |
Evaluation under mixed velocity commands
We compare the learned unified model with the heuristic-best baseline across commanded forward velocities while additionally sampling lateral-velocity and yaw-rate commands from (vy* ∈ [-0.4, 0.4] m s-1) and (ωz* ∈ [-0.4, 0.4] rad s-1), respectively. This setting evaluates robustness beyond straight-line forward locomotion. Lower CoT is better; higher survival and success rates are better.
| vx | STL-based unified model | Heuristic-best | ||||
|---|---|---|---|---|---|---|
| CoT ↓ | Survival ↑ | Success ↑ | CoT ↓ | Survival ↑ | Success ↑ | |
| 0.30 | 1.87 ± 0.06 | 1.00 | 1.00 | 2.55 ± 0.21 | 1.00 | 0.00 |
| 0.50 | 1.46 ± 0.04 | 1.00 | 1.00 | 2.11 ± 0.11 | 1.00 | 0.35 |
| 0.70 | 1.24 ± 0.02 | 1.00 | 1.00 | 1.83 ± 0.07 | 1.00 | 1.00 |
| 1.00 | 1.21 ± 0.02 | 1.00 | 1.00 | 1.74 ± 0.06 | 1.00 | 1.00 |
| 1.30 | 1.10 ± 0.01 | 1.00 | 1.00 | 1.76 ± 0.05 | 1.00 | 1.00 |
| 1.60 | 1.07 ± 0.01 | 1.00 | 1.00 | 1.74 ± 0.05 | 1.00 | 1.00 |
| 1.90 | 1.11 ± 0.01 | 1.00 | 1.00 | 1.72 ± 0.05 | 1.00 | 0.00 |
| 2.00 | 1.12 ± 0.01 | 1.00 | 0.80 | 1.69 ± 0.06 | 1.00 | 0.00 |
| 2.10 | 1.13 ± 0.01 | 1.00 | 0.00 | 1.69 ± 0.15 | 0.90 | 0.00 |
Locomotion Regimes
Walk-Trot Gait (vx = 0.4 m/s)
Trot Gait (vx = 1.2 m/s)
Bound Gait (vx = 1.9 m/s)